Replicating Anthropic research and other things
Whattup, this is my first time posting an organic journal entry. I’m writing this on the bus. I’ve been thinking about getting back into a project to replicate Anthropic’s work with superposition. I had a few small roadblocks, but I think things are going well.
Also, some reflections on my project from yesterday.
Reflections on Obsidian and GitHub Pages integration
I was proud because I went from idea to product on this in like 48 hours. The idea builds on a lot of tools I use at work but rarely at home.
When to use Docker
I think this was a good job for docker for a few reasons:
- Most/all of the operations can be handled with bash commands
- It involves multiple programs and system-dependent setup like installing obsidian-export and cron jobs
I still don’t totally understand when to use Docker, but I think it’s easy to make the case here.
TODO
I really need to implement automatic insertion of a table of contents. These notes will certainly get messy.
There also a lot of bugs, but the main workflow is pretty solid. It won’t handle the deletion of journal entries at all, but I expect that to be rare. It also won’t scale well as-is; it performs redundant operations on all journal entries. But the load is probably going to be negligible for a long time.
Also I really need to clean up the config, but at least I didn’t upload my GitHub token to remote.
Other remarks
I used GPT4 quite a bit in this project. Probably the #1 use case I’ve found for GPT is writing bash commands, but it was also nice for setting up the docker.
I’m not sure I have any next steps for this project at the moment. I think for now I’m gonna stabilize it and see if any problems or new use cases pop up.
Note to self: check if LaTex works. $\mathbb{L}$
Oh, and I changed the cron job to only run every 2 hours. I heard GitHub has a soft limit of 10 blog deployments per day, and they will get mad if you do it too much. Hopefully this will fly under their radar ;)
Replicating Anthropic’s superposition study
I was working on this a month or two ago and then got distracted. I actually logged most of my progress in a thread on The Philosopher’s Meme Discord server.
Model Architecture
The original paper actually has some ambiguities in the model architecture. It’s supposed to be a one-layer transformer. They describe the model as having “a residual stream dimension of 128 and an inner MLP dimension of 512,” and it uses ReLU activations. Here’s a pic from an Anthropic paper sketching their one-layer transformers. Ignore the “features” block. That gets implemented separately.

Embeddings and unembeddings are just linear layers.
There is still a free variable though; dim(residual stream) = C*E, where C is context size and E is embedding dimension.
I was kind of confused about this, because if the embedding is 8 dimensions, then the context size is only 16, which seems ridiculously small.
Also, how many attention heads should I use? Oh, and how do they handle positional embedding
I figure I can tune most of these things as hyperparameters, so I’ll try not to worry too much.
Here is my first draft architecture. I forgot to include the embedding step in this draft. It has since been fixed.
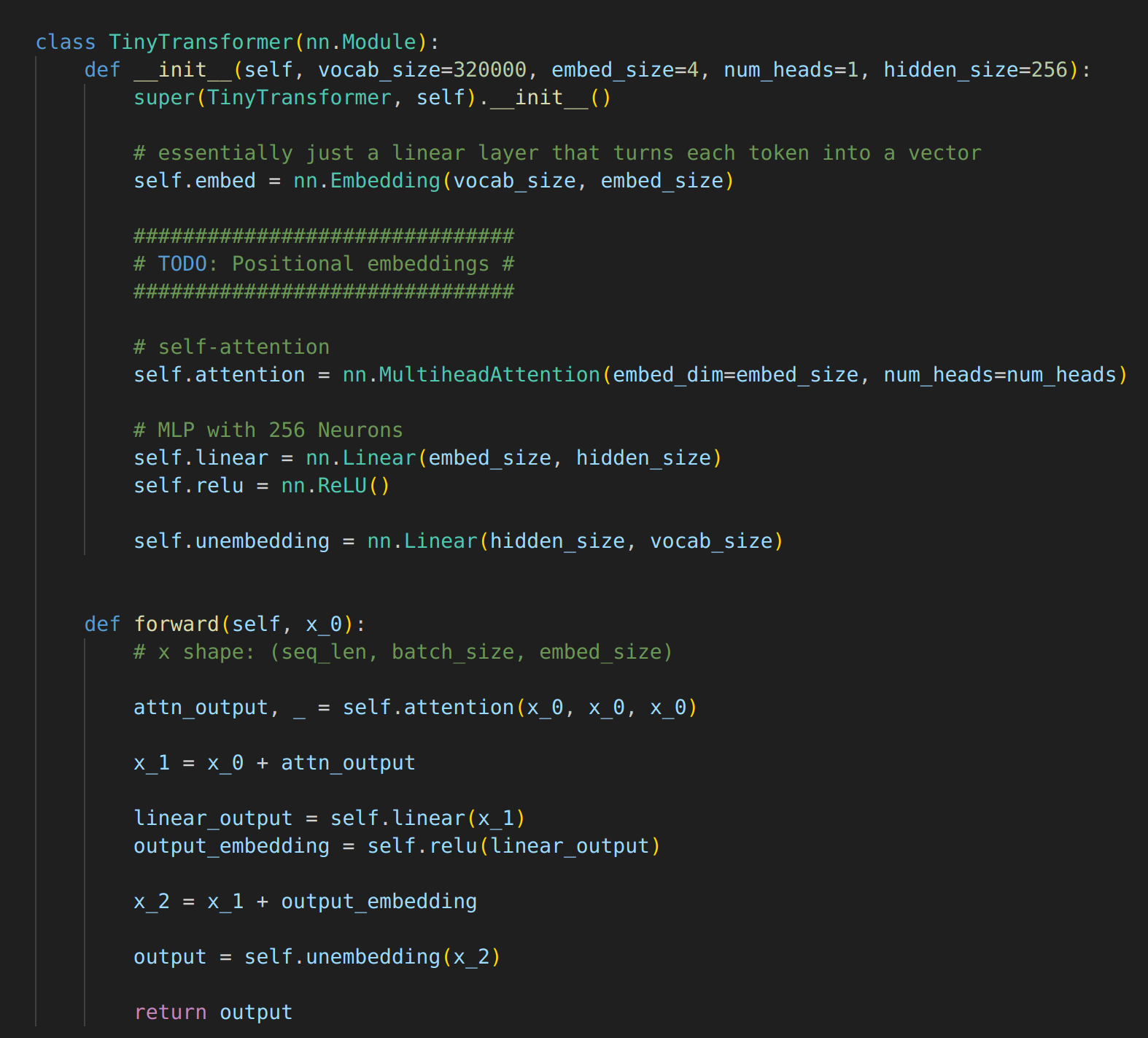
Training
I wasn’t sure if I’m supposed to apply some kind of masking during training of this architecture. I ended up deciding that I would skip masking. Instead, the model will always predict the token which occurs after the input context.
I was thinking about training on TinyStories. Just seems like a fun dataset. I need to work out a pipeline for tokenizing the dataset and then set up a training workflow.
Ideally I’ll train a few small runs to figure for the hyperparams and then scale up. I’m gonna make a point to try and integrate wandb for some pretty graphs.