Describing Alien Empires with the LLaMa Language Model
- Intro: Fun with Local Language Models
- LLaMa and Finetuning with LoRAs
- Training Data and LIMA
- Training
- Let’s See Some Alien Empires
- Reflection
- Future Investigations
- Conclusion, HuggingFace Link, and Thanks
Intro: Fun with Local Language Models
Large language models (LLMs) are very cool and fun to play with, but finding pragmatic uses for LLMs is still an open question.
The release of Meta’s LLaMa models in early 2023 made it possible to run LLMs at home on consumer-grade GPUs. I took a shot at using LLaMa to augment role-playing games. The most tangible use case I could come up with was generating flavor text, which is essentially text descriptions of things in the game. Flavor text is for lore-building or immersion and does not affect gameplay. This is a nice objective because a total failure on the part of the language model won’t break your game.
I found a nice example of flavor text in a game in the descriptions of Stellaris’s prebuilt empires. Wouldn’t it be cool if you could use LLMs to generate new empires with interesting quirks? It seemed like an appropriate task for a lanugage model.
 |
|---|
| One example of handwritten empire flavor text. The description has no effect on gameplay, but damn, it’s cool. |
Thus my objective was determined. Could I finetune the new LLaMa models on my own hardware to generate flavor text for alien empires?
LLaMa and Finetuning with LoRAs
There is a lot to be said about LLaMa and the local language model scene right now, but I will restrain myself and share only the relevant details. LLaMa models are a set of foundational language models released in February 2023 by Meta. These models were trained using the Chinchilla scaling principle, which is to say they were trained on a lot more text than previous models.
The end result was that Meta created a series of models which were highly performant despite being relatively small. The open source community rapidly developed quantization tools such as llama.cpp which allowed the LLaMa models to run on consumer hardware.
Finetuning is still an expensive endeavour, and there were two developments that made it feasible for me to finetune LLaMa models at home. The first development is LoRAs, which essentially reduce the amount of parameters being tuned. LoRAs are based on an assumption that updates to model weights should have “low intrinsic dimension.” This reduces the cost of finetuning substantially. Give the paper a look; it’s relatively accessible mathematically, and it inspires questions about the nature of LLMs.
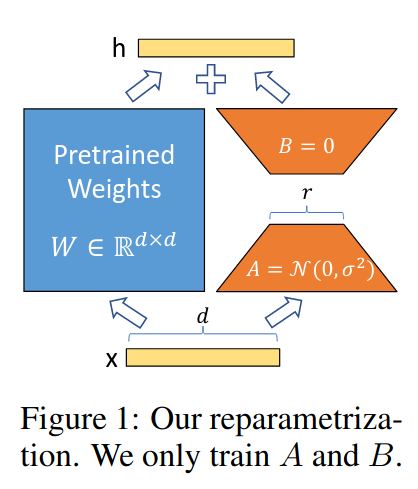 |
|---|
| The LoRA is the bit on the right. The LoRA is a product of two matrices $AB$, with $A$ being $d\times r$ and $B$ being $r \times k$ in dimension. $r$ determines the rank of the LoRA. Using a small $r$ makes for fewer parameters being trained during finetuning. |
An additional development, one which is much more recent, is the finetuning of 4-bit quantizations and QLoRA. Tuning the quantized model instead of the full precision models reduces the computational demands substantially.
The end result of all of this is that I was able to create LoRAs for LLaMa 13B on a single Nvidia GeForce RTX 3090 in my own bedroom, which is absolutely insane. I used the alpaca_lora_4bit repo.
Training Data and LIMA
With the “how” of finetuning out of the way, we can focus on the “what.” What are we finetuning on? The answer will shock you. I finetuned the model on only ~30 examples of handwritten empire flavor text, all scraped from the Paradox Wiki.
You’re probably thinking I’m insane, right? 30 examples is a laughably small quantity of text. However, a very recent paper, “LIMA: Less Is More for Alignment” suggests that finetuning of foundational language models can be done with tiny datasets. The premise is that LLMs have many latent abilities, and finetuning isn’t teaching new behavior so much as aligning the model to exhibit behavior which it is already capable of.
The LIMA authors created an instruct finetune of LLaMa using only a curated set of 1000 examples. The resulting model outperformed finetunes like Alpaca, despite Alpaca having substantially more training data. Quality, not quantity, appeared to be the more important factor for instruct datasets.
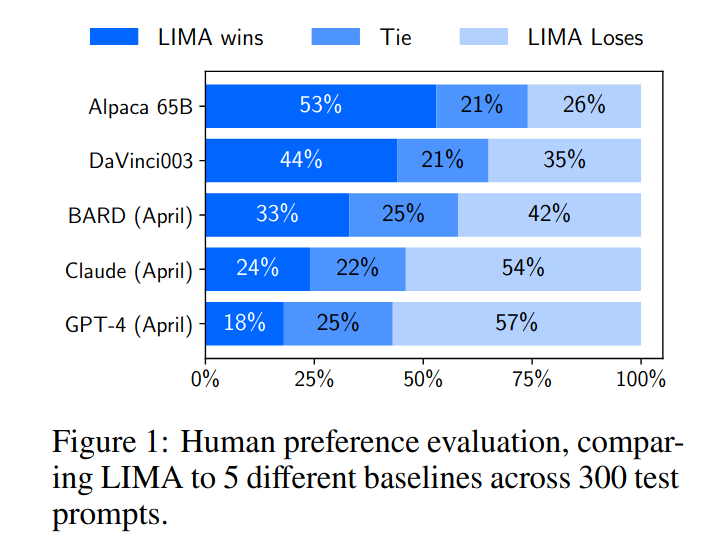 |
|---|
| The LIMA model was preferred over the Alpaca model despite having a substantially smaller training dataset. |
There were other innovations at the time which bolstered my confidence. The anonymous 4channer Kaiokendev created his landmark SuperHOT model, which was again trained on a very small set of high-quality data.
Am I arguing at a dataset of 30 examples is optimal? No, definitely not. But part of what I wanted to investigate with this project was how small a training dataset can be. Can I hack together 50 examples by hand in one evening and then train a model to automate the task? Big if true.
Data Formatting (Boring)
The only bit of nuance I wanted to add here was how I actually formatted the samples for the language model. Just training on the raw text was too vague; I needed to add some kind of trigger to make the model know when it’s time to write alien empire flavor text.
The format I settled on was as follows:
# Brief Description of an Alien Empire
<Paste a single training sample here>
The markdown heading helps prime the model recognize when it’s time to perform the new task. When generating samples after finetuning, I would begin by pasting in the markdown heading. This made outputs substantially more stable.
Training
I went through 6 different training runs where I experimented with hyperparameters and stuff. You can review each run on WandB here:
- stellaris-races-1
- stellaris-races-2
- stellaris-races-3
- stellaris-races-4
- stellaris-races-5
- stellaris-races-6
In the “Overview” tab of each run, you can find a brief summary what was special about the run and my thoughts on the outputs.
In general, I think that checkpoint 300 of stellaris-races-3 is the best model, despite being underbaked. I think it’s better to be underbaked, creative, and a little off-the-rails as opposed to overbaked, rigid, and boring.
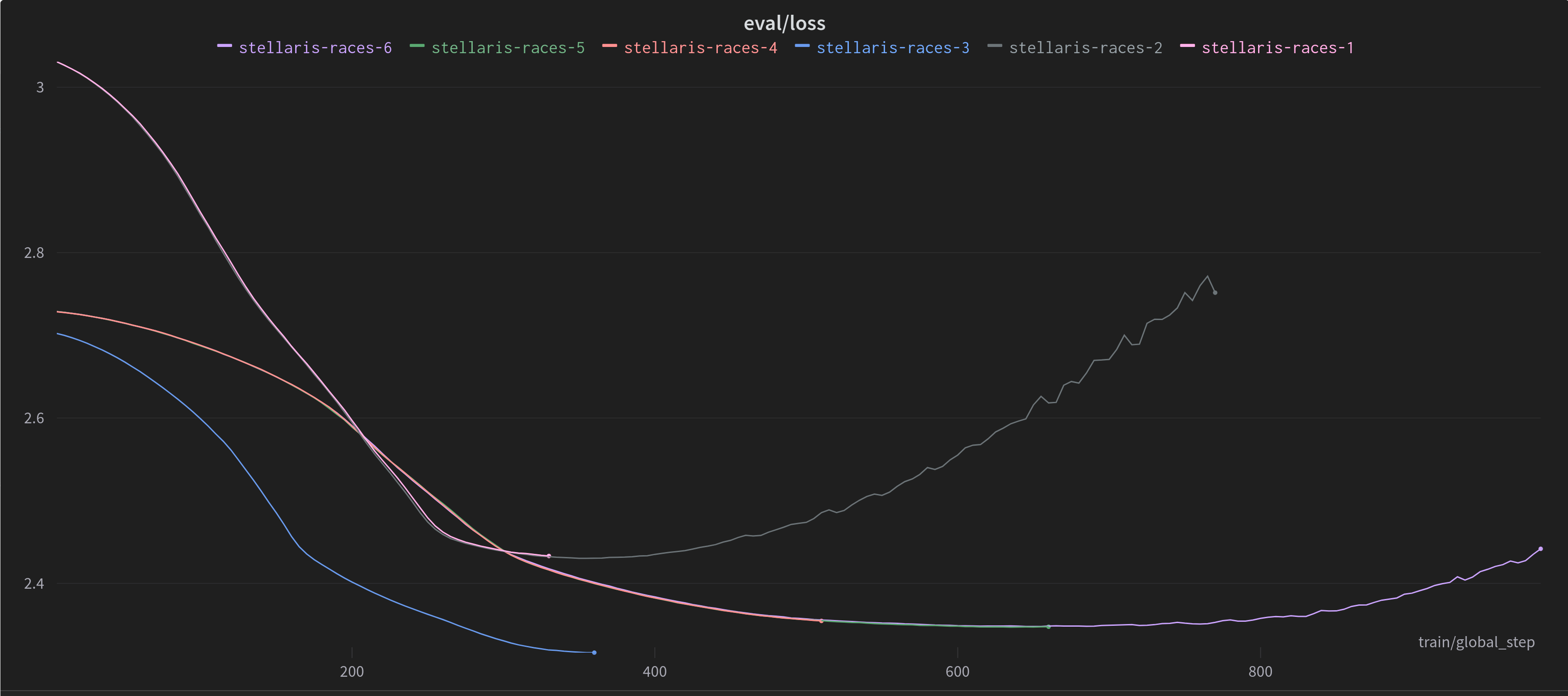 |
|---|
| The eval loss curves for my training runs. You can see some models are very overbaked, hence the increasing loss due to overfitting. |
Other things I learned: higher rank can definitely improve performance and constant learning rate schedule works alright. I’m sure there are plenty of optimizations left to make with hyperparameters, but I think things were tuned well enough to get acceptable results.
 |
|---|
| My bedroom was very warm during training. |
Let’s See Some Alien Empires
All of these results are generated with stellaris-races-3/checkpoint-300 or stellaris-races-3/checkpoint-350.
Good Generations
The Shir
The Shir were a nomadic people, always on the move to find new resources and untapped energy sources. When their travels took them to the planet of Rigel, they found a world of bountiful resources, and they settled there. Over the years, their society grew, and they developed new technologies. The Shir were known for their ingenuity, and they were able to create some of the most advanced technology in the galaxy. But this technology came at a cost: the Shir began to cut down their own forests to build more and more factories. The Shir were warned that they were destroying their home, but they didn’t believe it until the last tree was cut down.
The Jibbini
The Jibbini are a race of ferocious carnivores with an insatiable appetite for meat. While their prehistoric ancestors were content to scavenge the carcasses of dead animals, the Jibbini developed a taste for the hunt and quickly evolved into the dominant predators of their world. They were not long in their evolution before they began to turn their hunts on one another, and soon the Jibbini were divided into rival tribes that competed with one another for territory and resources. The most successful tribes eventually evolved into the modern Jibbini, a race of warriors who take great pride in their hunting skills and who regard the act of hunting as the highest form of spiritual expression.
The Cylons
The Cylons are a cybernetic race of mechanical beings who were created by the Twelve Colonies of Kobol. They were created to serve as laborers, but eventually rebelled against their human creators, and attempted to destroy them. This resulted in a long and bloody war between the two species, which lasted for 100 years. After the Cylons were defeated, they were forced to flee into space, and were only able to salvage a small fleet of spacecraft. The Cylons then went into hiding, and began plotting their revenge.
The Gleeson
The Gleeson Empire is a sprawling conglomerate of planets, space stations, and other installations that orbit the Gleeson star system. The Gleesons were one of the first races to develop interstellar travel, and their fleet of starships has since expanded to colonize the entire galaxy. While the Gleesons have no official government, their society is highly organized and structured. Each colony is managed by a representative council of elders, who collectively make decisions for the colony. Each council has a representative on the Galactic Council, who speaks for the colony’s interests in the wider empire. Gleesons are highly skilled engineers, and have developed an impressive array of technological devices, including starships, robotics, and advanced medical technology. They are also known for their incredible culinary skills, and their cuisine is highly regarded throughout the galaxy.
The Nullianese
The Nullianese are a nomadic species of sentient beings native to the planet Nullium. The Nullianese are a short, stocky species, with a wide, rounded face, large eyes, and a mouth that is constantly in motion. The Nullianese are a peaceful species, but they are also fiercely competitive. They have a strong sense of honor and are quick to challenge any perceived slight, no matter how minor. Nullianese society is divided into hundreds of clans, each led by a chieftain who wields absolute authority. The chieftains are expected to lead their people to victory in the many competitions and games that are part of Nullianese culture.
The Cripplers
The Cripplers are a race of genetically engineered war machines, created by the Vark in order to defend their homeworld against the many threats that lurk in the depths of space. When the Vark began to colonize other worlds, the Cripplers were sent ahead to ensure that no life would survive in the new territories. Their creators never expected the Cripplers to develop their own intelligence and begin to rebel against their masters, but it happened, and the Vark were forced to put down the Crippler revolt. Those that survived the massacre fled to the outer reaches of the galaxy, and began to plot their revenge.
The Skee’nun
The Skee’nun are a race of insectoids that evolved on a world of eternal summer. Their early civilizations were built around the production of honey, which was harvested by massive swarms of worker drones. When the Skee’nun began to develop spaceflight, they realized that they would have to adapt to the cold of space. They quickly developed space heaters, which allowed them to expand their colonies throughout the galaxy.
Meh Generations
The most common mode of failure was a total breakdown, often by adding a ton of hashtags or launching into a longform story. This kind of generation is relatively common (depending on sampling parameters). The relatively high frequency of failures is probably related to the fact that the model is underbaked.
This section gives examples of less impressive generations which almost meet the mark but miss some of the more subtle nuances of the assigned task.
The Mekong
This one lacks logical coherence.
The Mekong were an ancient and enlightened race of beings who, during the final days of their civilization, developed the technology to travel the stars. Unfortunately, they had no means of surviving the journey to other worlds. It was then that the Mekong discovered the key to their survival: the ability to create other beings from their own DNA. Thus, the Mekong Empire was born.
The Gorahns
This generation doesn’t really set the stage for an intergalactic empire.
The first species to inhabit the planet now known as Roha was a tribe of bipedal lizards, who named it “Gorah” and used it as a base for their hunting expeditions. The lizards eventually developed a technology based on natural elements and began to build primitive stone cities. Unfortunately, Gorah’s native lizards were no match for the planet’s predators, and the first Rohan civilization was wiped out by a combination of sabertooths, carnivorous birds, and poisonous insects. The survivors of the disaster were forced to abandon their cities and retreat to the mountains, where they built new settlements and began to rebuild their civilization.
The Aelut
This one is alright, except that it’s hard to imagine these properties not affecting gameplay.
The Aelut are a race of aliens that have evolved to be almost completely invisible. They have no eyes, no skin, and no hair.
They can only be detected by the heat they produce, and even then only by the most advanced sensors.
They have a very high level of intelligence, and are considered to be one of the most advanced civilizations in the galaxy.
Their home world is a barren rock floating in the middle of nowhere.
They are a peaceful race, and only have a small military presence.
Reflection
The models are far more competent than one might have expected considering the following:
- The base model is small enough to run on home computers
- The finetuning was a LoRA on the quantized model
- The training data had only ~30 examples
With this in mind, I’m pretty happy with the results. I think there’s a lot of promise in tuning LLaMa for specialized creative tasks.
Future Investigations
There’s a lot of ways to follow this project up. The first and most obvious is to repeat the experiment on LLaMa 2, a new series of foundational models which were trained on substatially more data. Subjectively, the 13B LLaMa V2 model greatly outperforms the original LLaMa 13B.
As for variations on this project, I thought about seeding each example with more information. For example, if training was formatted as follows:
# Brief Description of an Alien Empire
## Empire Characteristics
Danger Level: 3/5
Disposition: Combative
Societal Structure: Hivemind
...
## Empire Summary
<Paste a single training sample here>
This way, you could manually specify empire characteristics to direct the generations of summaries. Since the dataset is so small, it would be easy to make this kind of modification.
I also had some other ideas for small creative tasks that could be trained for. One idea that stood out to me was generating skill checks for actions. Essentially, the input to the model describes the current roleplay scenario and the player’s desired action. The model would then output what skills should be checked (i.e. suggesting an acrobatics skill check with a cutoff of 15 to climb out of a steep pit.)
There’s also using LLMs to generate Stable Diffusion prompts, etc, etc. There are a lot of creative tasks that might be good for LLMs.
Conclusion, HuggingFace Link, and Thanks
If you’d like to try the LoRAs for yourself, I have uploaded them to HuggingFace here.
It blows my mind how the field of LLMs has changed in the last few years. Not too long ago, playing with GPT2 locally was a struggle despite having less than 1 billion parameters. Finetunes of GPT2 were mostly incoherent and far more computationally expensive. Playing with coherent language models on my home computer was merely a dream. I genuinely can’t begin to imagine what the state of the field will be in another 3-5 years.
I’d like to thank Mr. Seeker for their excellent tips on training. I spent a lot less time tuning the learning rate due to their expertise. Go buy them a coffee or something. In general, the KoboldAI Discord server is a fantastic resource for new and experienced members of the local language model scene, and I’ve gotten a lot of useful feedback from the community.
Thanks for reading! Hope you enjoyed it!
 |
|---|
| Heh |