What is an object? Object Detection and Philosophy… In Runescape
- The means justify the ends
- Extracting bounding boxes from Runelite
- Approximating whether an object is visible
- Training an object detector
- Conclusion
The means justify the ends
This is a story about a very dope problem I stumbled upon while doing very dumb shit.
First: the very dumb shit.
I wanted to train an object detection algorithm to detect interactible objects (as opposed to scenery) in Runescape. I did this in two parts:
1) Collect training data for an object detection algorithm
2) Implement and train an object detection algorithm
The first obvious question was data collection. Where in the world do you get training data for detecting interactible objects in Runescape? I programmed a Runelite plugin using the Runelite API which extracted “ground truth” data from the Runelite game client. This ground truth data contained bounding boxes around all interactible objects in the player’s field of view.
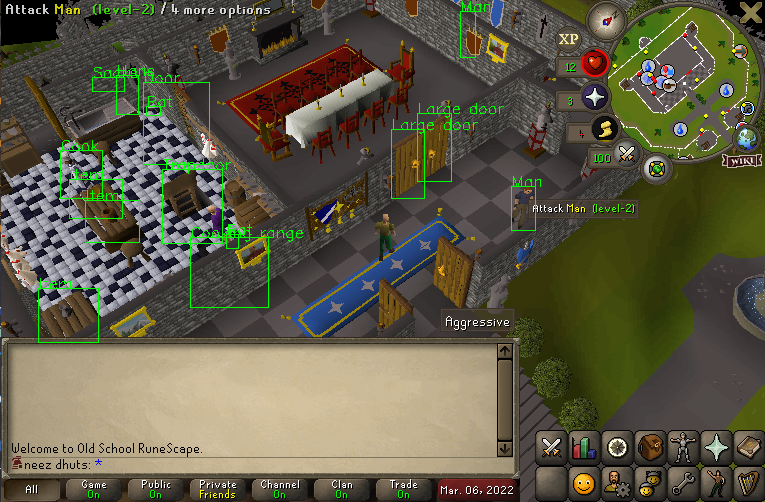 |
|---|
| An example of the data that can be extracted from Runelite |
Collecting this ground truth data was not straightforward. I had to modify some existing Runelite plugins to calculate bounding boxes around objects of interest.
Now: the dope problem.
Once I had this data, I discovered we did not have sufficient information: the data describes all objects in the camera’s field of view, even if they are totally obscured from the player’s view. This is a problem, because obviously (although I never realized it until this problem popped up) I wanted to train the object detection algorithm to detect visible objects.
So I ended up having to solve the visible object problem:
- Suppose you have an image containing some object. Suppose the object might be partially or totally obscured by other objects in the image, but you aren’t sure. In fact, suppose you don’t even know what the object is supposed to be. However, suppose there is one thing you know: You know where the object would be in the image if it were visible in the image. Can you guess whether the object is visible by looking at the image?
Before we solve this problem, I’ll talk about how I got the data. After that, though, we’ll start filtering visible vs invisible objects and then use the resulting data to train a YOLO classifier to identify interactible objects in Runescape.
Extracting bounding boxes from Runelite
Here’s the nitty gritty about how I got this data out of the game. You can skim this if you want, it’s cool, I get it.
Calculating bounding boxes
I discovered that Runelite has a built-in plugin called NPC Indicators which visually displays “convex hulls” around NPCs. This kind of calculation is quite similar to determining bounding boxes around objects, so it seemed obvious to start by attempting to modify this plugin.
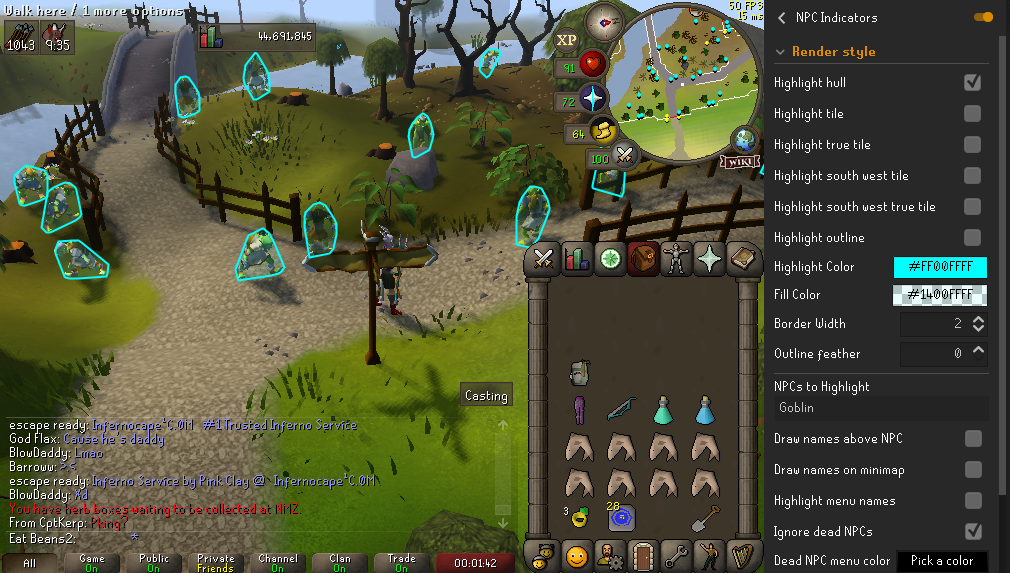 |
|---|
| A default Runelite plugin that renders convex hulls around NPCs |
I added a new setting to the plugin that calculated bounding boxes. Runelite’s API limits what data you can extract from the Runescape client, so I ended up having to start with the convex hull and calculate the equivalent bounding box. It was a pretty simple job, all things considered.
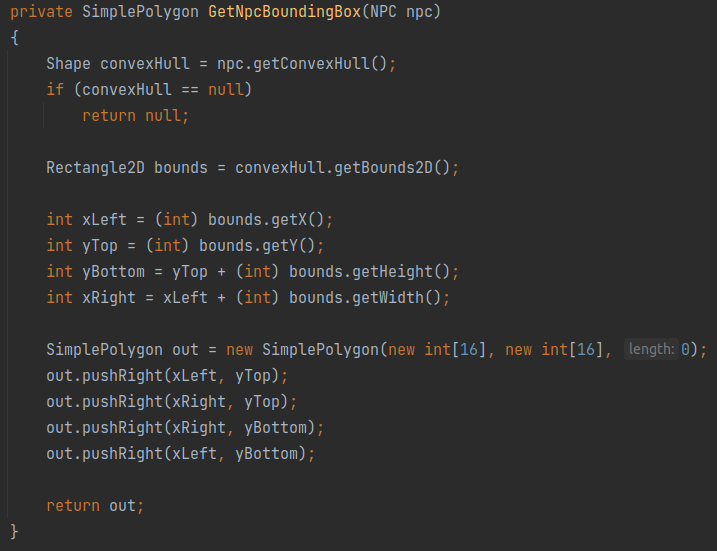 |
|---|
| Quick code for turning a convex hull into a bounding box |
The results were not bad!
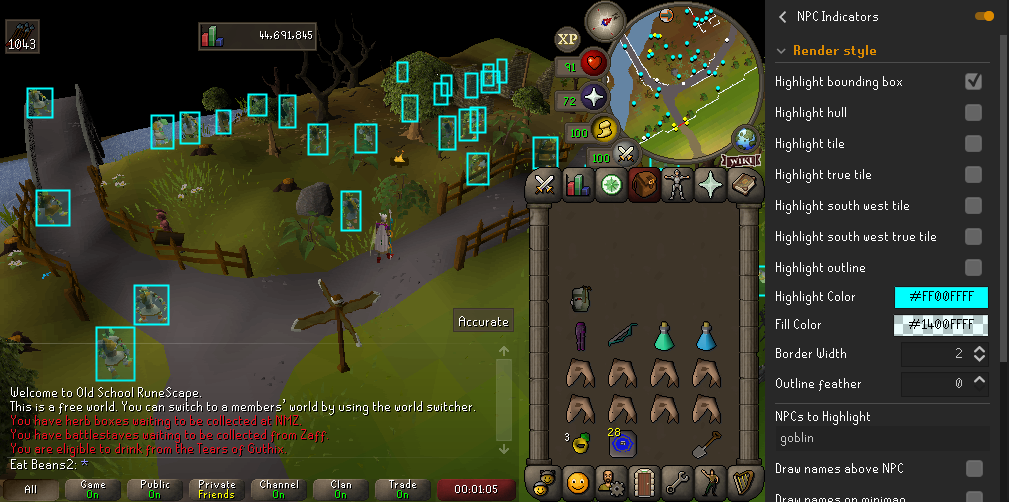 |
|---|
| My modified plugin that calculates bounding boxes around NPCs |
Exporting the data
This bounding box data is ready to be extracted to CSV files. I extended the plugin so that it applied to all interactible objects instead of just non-player characters (NPCs). This was boring and not worth talking about. Then, I modified the built-in Screenshot plugin so that it periodically took screenshots and saved the corresponding bounding box data. The result was some nice-looking ground truth data:
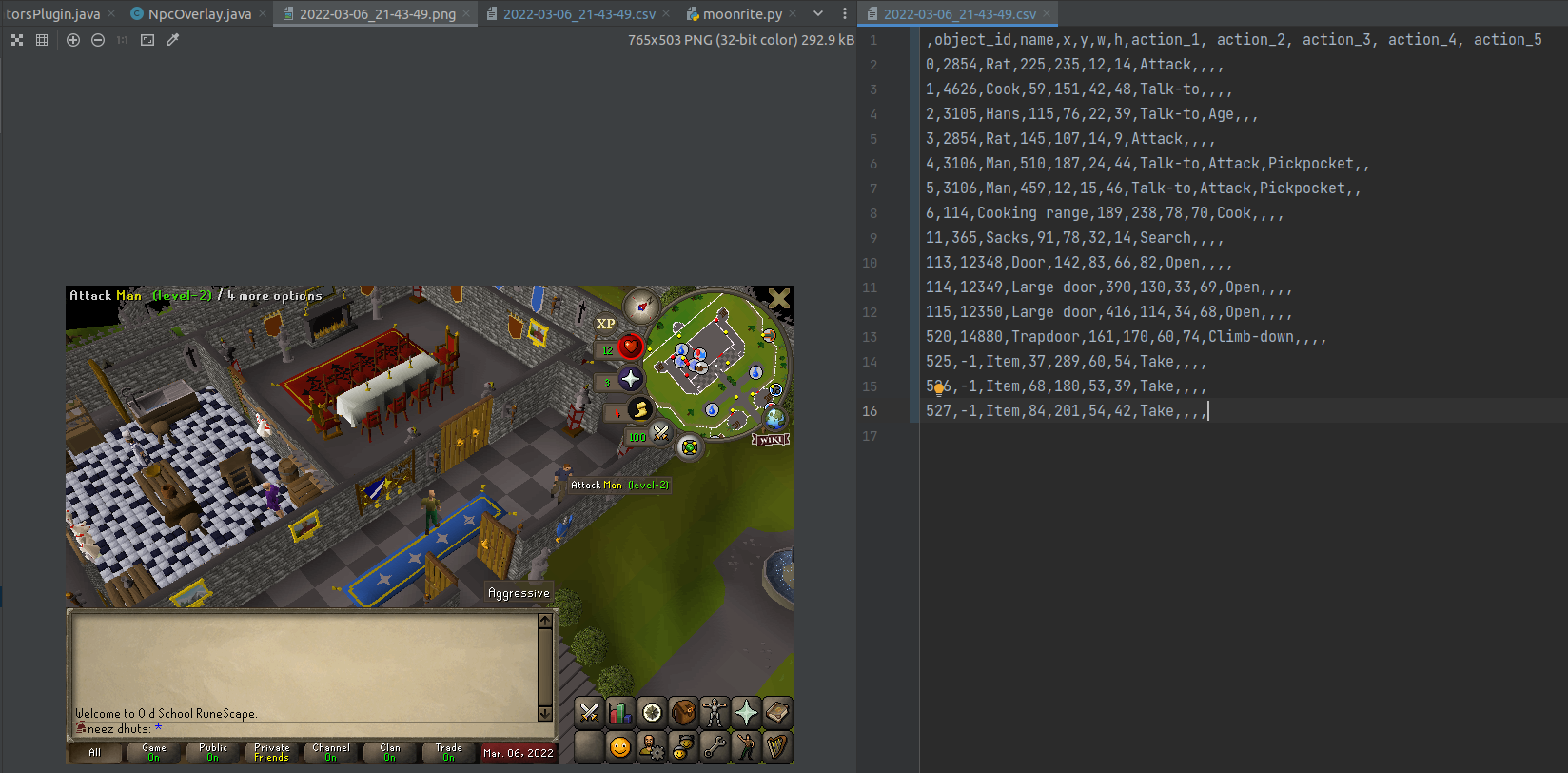 |
|---|
| A sample of the training data in its natural form: image and csv pairs |
Let’s plot it:
|
|---|
| Visualizing the training data we obtained. Clearly it’s not what we wanted |
So now I had arrived at the problem. These bounding boxes included objects which were completely obscured from view! Just look at the Man on the top-right of the screen:
 |
|---|
| This guy is not visible |
This was unacceptable as ground truth training data. It would have been nice if I could ask the game for this information, since surely it knows which objects are visible. Unfortunately, I searched and searched, but I couldn’t find a way to determine if objects are visible using the Runelite API. So what can we do?
Approximating whether an object is visible
Defining images and objects
Yeah, this is where things got a little weird. I wanted to take a down-and-dirty, model-based approach to filtering this bounding box data into “visible” and “not visible.” How would I build a model?
Suppose we’re dealing with an $n\times m$ black-and-white image
\[I(x,y): \mathbb{Z}_n \times \mathbb{Z}_m \rightarrow \mathbb{Z}_{255}\]By definition, $I(x,y)$ tells the intensity value for pixel $(x,y)$. We know certain subsets of the pixels constitute visible objects. We assume visible objects are rectangular regions of pixels. Then there are an unknown amount, $k$, of rectangular regions of the image ${r_0,r_1,\ldots,r_p}$, where $r_i\subset \mathbb{Z}_n\times\mathbb{Z}_m$, which are visible objects.
What is an object like?
What can we assume about visible objects? One assumption is that subregions of a visible object have similar intensity histograms. Let’s look at an example from the previous images. Here we compare the distribution of intensities among the top and bottom halves of this goblin.
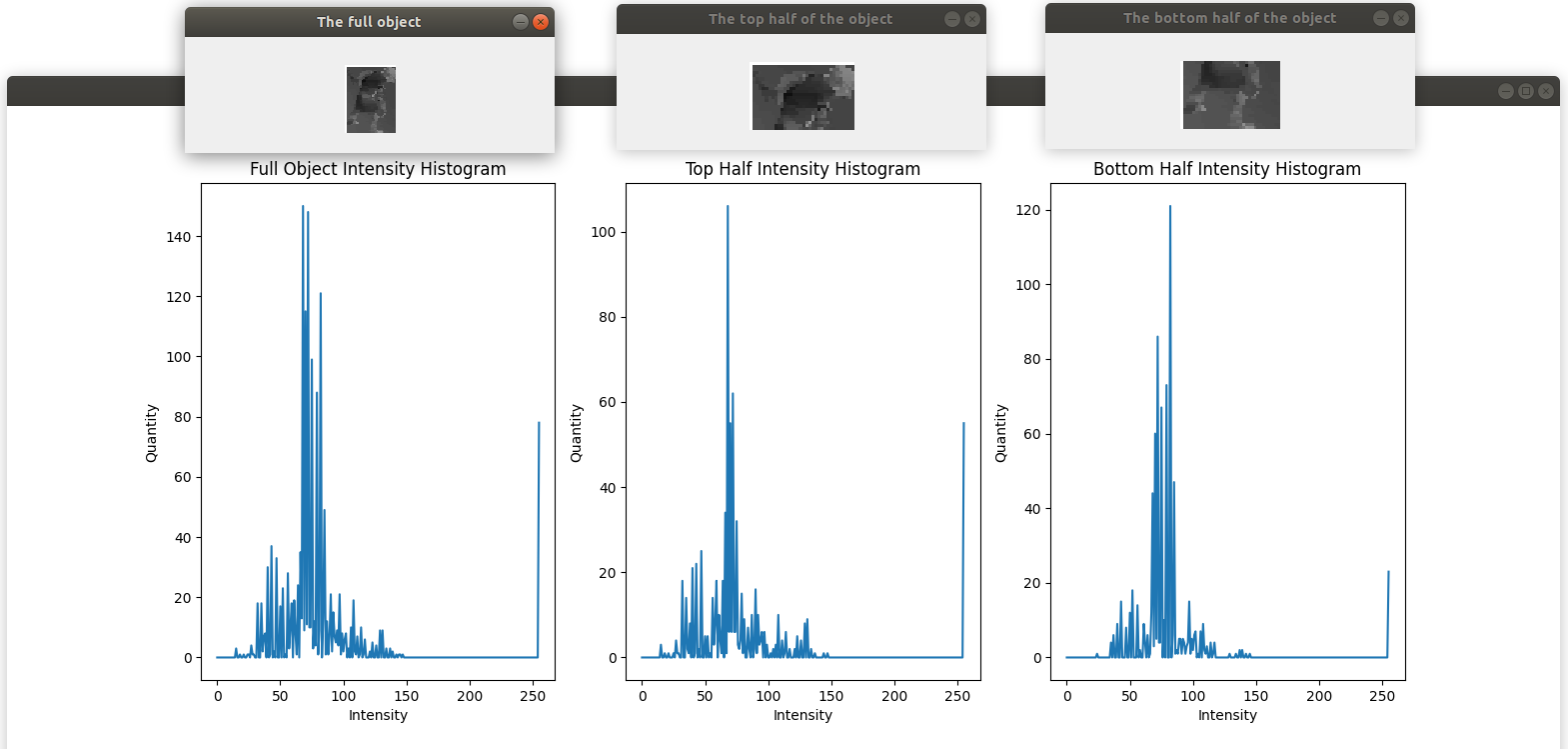 |
|---|
| Regions from the same object tend to have similar intensity histograms |
While they’re not exactly the same, there’s certainly similarity. We can approximate the intensity similarity using histogram intersection:
\(s_{intensity}(r_i, r_j) = \sum_{k=0}^{255}\text{min}(t_i^k,t_j^k)\) Where $t_i^k$ is the quantity of pixels in region $r_i$ with intensity $k$. The similarity score of the top and bottom halves of this goblin is 398.
Another similar concept is texture similarity, which uses the spatial intensity gradient instead of the raw intensity values. We can also generalize these concepts to color images.
Surprise! We’re talking about region proposal!
Thinking about “what is an object” reminded me of some algorithms I saw in my computer vision class. This led me to discover the Selective Search Algorithm (SSA), which is exactly what we were looking for.
Region proposal has been thoroughly studied in computer vision. According to the paper describing the SSA, region proposal concerns “generating possible object locations for use in object recognition.”
The SSA used image segmentation along with metrics such as color similarity, intensity similarity, and texture similarity to generate a large set of regions. Region proposal algorithms tend to produce lots of false positives, as they cast a wide net and let a down-stream classifier filter these further.
 |
|---|
| Region proposals from the original SSA paper |
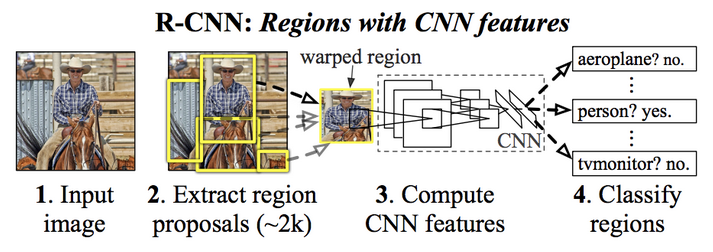
Indeed, early object detectors were basically just model-based region proposer followed by a classifier. For example, the R-CNN operated in two stages (image source here:
1)Generate a ton of region proposals from the image using Selective Search Algorithm
2) Resize each region to some fixed dimensions and feed it into a CNN classifier
The visibility model
So, how does this relate guessing whether an object is visible given an image and the object’s bounding box? This is the “model” I settled on:
- An object is visible if and only if its bounding box is (approximately) generated by Selective Search Algorithm
So I generated region proposals using SSA, and if any of these proposals had an Intersection over Union (IoU) with an object bounding box close to 1, then we call them a match and declare the object visible.
That’s it! Sounds stupid, right? Well fuck off, I was pretty proud of this little trick.
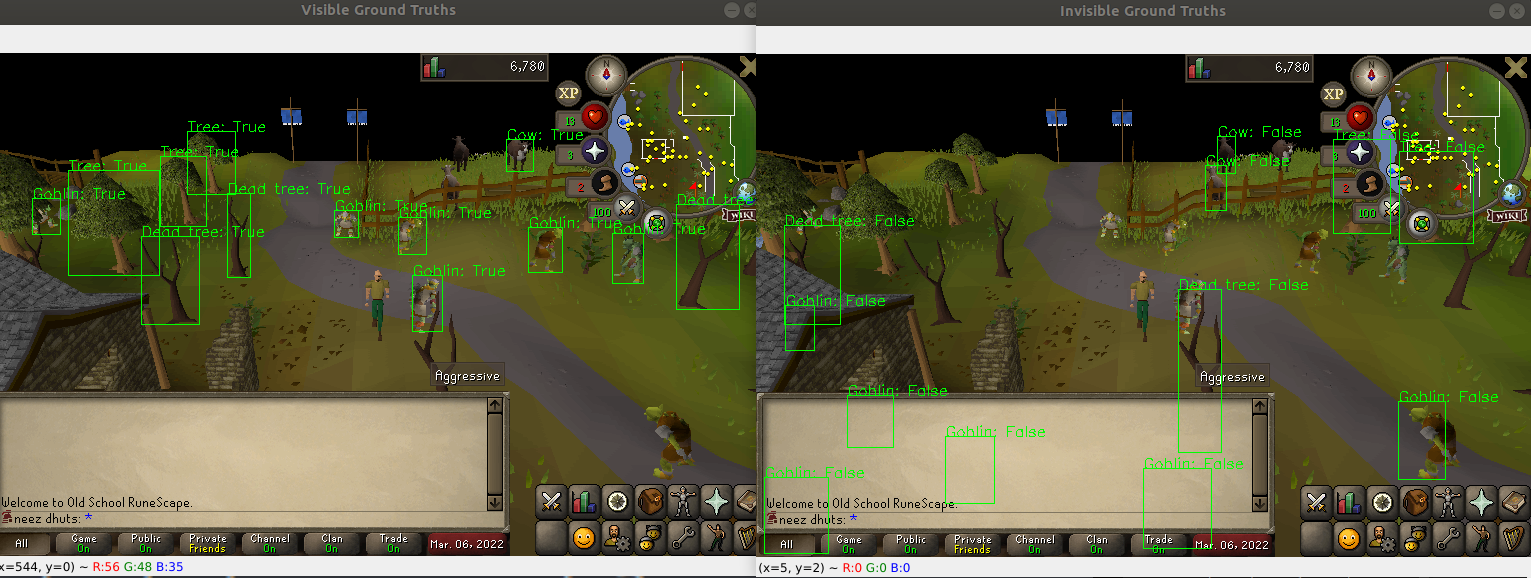
So does it work? See for yourself:
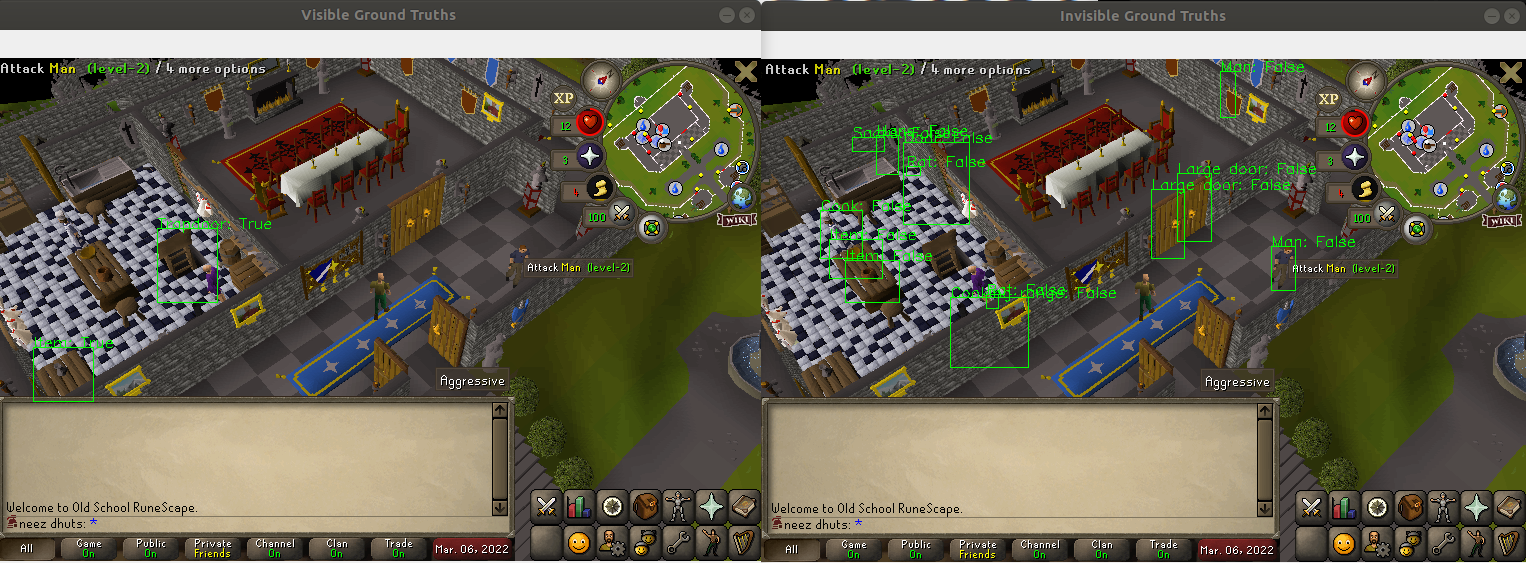 |
|---|
| Left: Objects labeled “visible” by SSA. Right: Objects labeled “invisible” by SSA |
 |
|---|
| Left: Objects labeled “visible” by SSA. Right: Objects labeled “invisible” by SSA |
Come on, that’s not bad! Maybe it’s a little overly cautious, but I think this will filter out a nice dataset of visible objects! So that’s the trick! That’s how I created training data for visually detecting interactible objects in Runescape.
Training an object detector
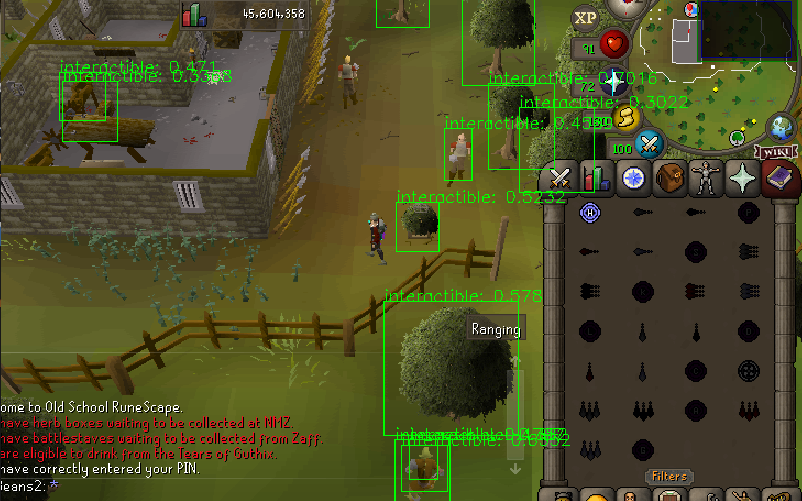
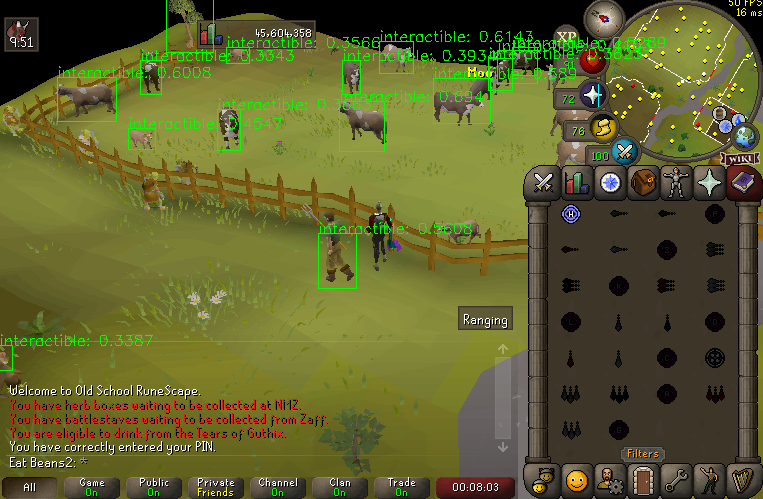
I used YOLOV5 and trained on a bunch of training data collected from around Lumbridge area in Runescape. The results were not too bad:
 |
|---|
| Using a trained YOLOV5 to detect interactible objects |
 |
|---|
| Using a trained YOLOV5 to detect interactible objects |
Nobody’s calling it perfect, but it’s pretty fast and not terribly inaccurate! This thing is pretty good at guessing what objects you can click in Runescape.
Conclusion
There is no conclusion. The human condition drives us forward, hurtling ourselves blindly into the unknown. I leapfrog from idea to idea, and each hop manifests ripples on the surface of the water. These are my signature, my proof that I was here. It seems you have found one of my ripples.